O modelo dos K vizinhos mais próximos, do inglês K-Nearest Neighbors (KNN), é um algoritmo amplamente reconhecido por sua versatilidade e simplicidade. Ele trabalha com a ideia de proximidade no espaço das características. A premissa fundamental do KNN é que dados semelhantes tendem a estar localizados próximos uns dos outros. Ao considerar os K vizinhos mais próximos, o algoritmo usa essas informações para fazer previsões ou classificações sobre novos dados.
Aplicações do modelo KNN
O modelo KNN possui diversas aplicações práticas. Na classificação de textos e e-mails, ele identifica spam ao comparar mensagens com aquelas previamente rotuladas. Em reconhecimento de imagens, facilita a identificação de objetos e padrões ao comparar características visuais com um banco de dados conhecido. No campo da saúde, o KNN auxilia no diagnóstico de doenças analisando sintomas e históricos de pacientes semelhantes. Em sistemas de recomendação, como os da Netflix e Spotify, o algoritmo sugere produtos com base nas preferências de usuários similares. No setor financeiro, o KNN é utilizado para avaliar o risco de crédito, comparando perfis financeiros para prever a probabilidade de inadimplência.
Como é a implementação do KNN?
O primeiro passo é definir o número de vizinhos, representado por “K” no algoritmo KNN. Em seguida, o algoritmo calcula as distâncias entre a nova observação e todas as observações do conjunto de dados. Após o cálculo das distâncias, o próximo passo é selecionar os K vizinhos mais próximos. Apesar da distância euclidianda ser a mais comum, também existem outras muito utilizadas como: Distância de Manhattan, Distância de Minkowski, Distância Cosseno, entre outras.
Suponha que temos um novo dado, representado pelo círculo cinza, que queremos classificar como Classe A (círculo laranja) ou Classe B (círculo azul). As observações existentes foram plotadas de acordo com as variáveis X e Y, conforme gráfico abaixo:
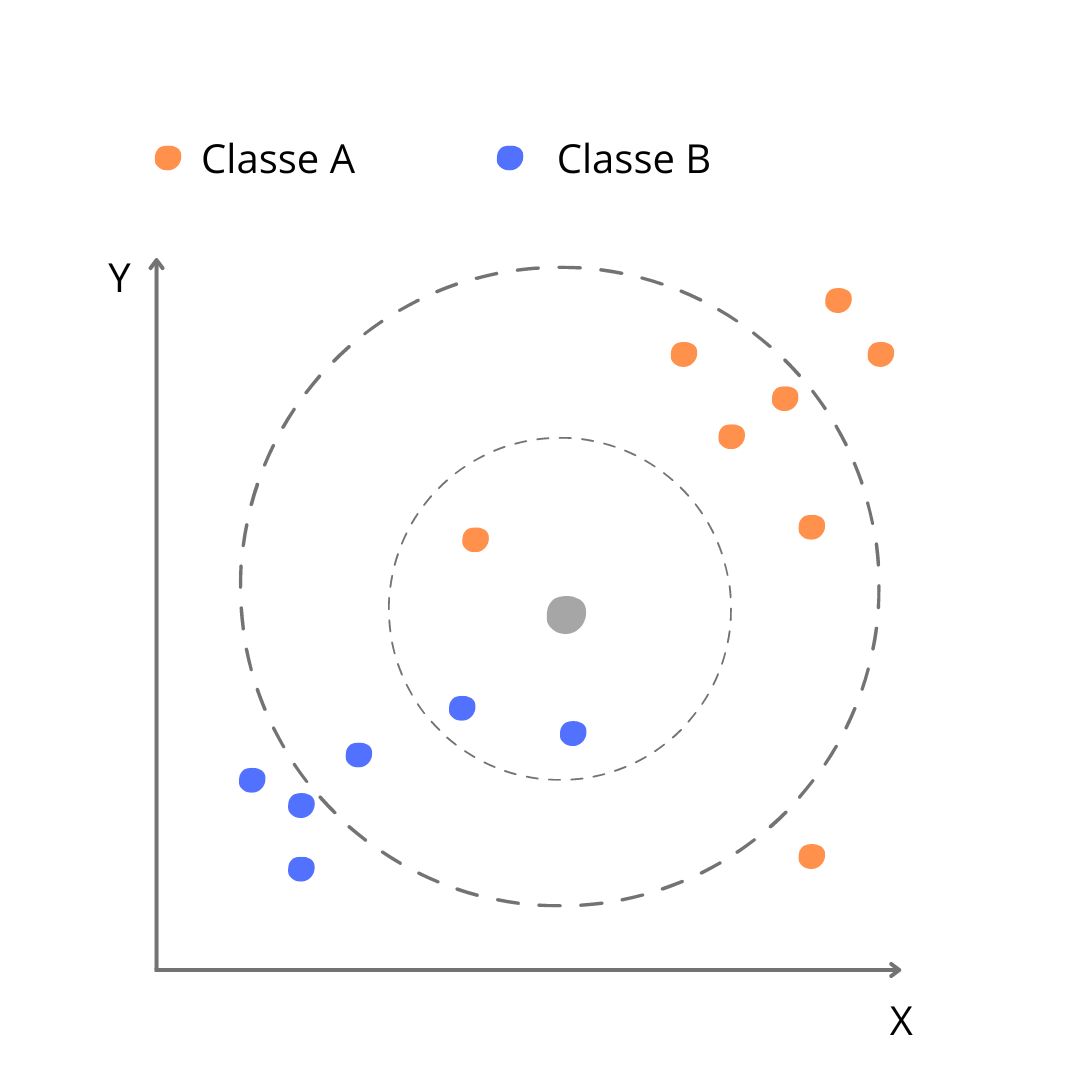
No primeiro cenário, com K=3, após calcular todas as distâncias euclidianas entre o ponto cinza e os demais pontos, a seleção dos vizinhos mais próximos inclui um ponto laranja e dois pontos azuis. Com base nessa seleção, o algoritmo classifica o ponto cinza como azul (Classe B). No entanto, ao ajustar K para 6, a seleção passa a abranger dois pontos azuis e quatro pontos laranjas, resultando na classificação do ponto cinza como laranja (Classe A). Então, como posso saber qual é o melhor K?
Pré-processamento e Validação dos Dados
Antes de aplicar o algoritmo KNN, é essencial realizar um pré-processamento adequado dos dados para garantir resultados precisos e confiáveis. Esse processo geralmente envolve a normalização ou padronização dos dados, uma vez que as características podem estar em escalas diferentes. Por exemplo, uma variável pode ser medida em milímetros, enquanto outra é expressa em quilogramas. Para evitar distorções nos resultados, é necessário ajustar essas escalas, assegurando que todas as características contribuam de maneira equitativa no cálculo das distâncias.
Além do pré-processamento, a validação dos dados é crucial para avaliar a performance do modelo de forma precisa. A validação cruzada é uma técnica eficaz que divide o conjunto de dados em várias partes. O modelo é treinado em uma parte dos dados e testado nas partes restantes, repetindo esse processo para todas as combinações possíveis de treinamento e teste. Esse método oferece uma avaliação mais robusta e ajuda a evitar o overfitting, que ocorre quando o modelo se ajusta excessivamente aos dados de treinamento e falha em generalizar para novos dados. Ajustar o valor de K e aplicar técnicas de validação apropriadas pode melhorar significativamente a performance e a confiabilidade das previsões.
Considerações sobre o modelo
Apesar de ser muito eficiente e prático, o custo computacional pode se tornar elevado quando lidamos com grandes volumes de dados, devido à necessidade de calcular múltiplas distâncias. A escolha do valor de K também é crucial: um K muito pequeno pode resultar em sensibilidade excessiva a ruídos, enquanto um K muito grande pode suavizar detalhes importantes e comprometer a precisão. Além disso, o KNN tende a funcionar melhor com um número reduzido de dimensões, pois quando enfrentamos muitos atributos, a performance pode ser prejudicada.
Conclusão
O KNN se destaca como uma ferramenta poderosa e versátil para classificação e regressão, oferecendo uma abordagem intuitiva e eficaz para análise de dados. Sua simplicidade na implementação e a capacidade de lidar com dados variados tornam o KNN uma escolha popular em muitas áreas. No entanto, para garantir que o modelo forneça resultados precisos e confiáveis, é fundamental realizar um pré-processamento adequado dos dados, como normalização e padronização, e aplicar técnicas robustas de validação.